The Data: Exploratory data analysis and pre-processing¶
The Yelp Dataset Challenge dataset provides information on a subset of its
- users
- businesses
- reviews and ratings
- tips
- check-ins
It includes data from 10 cities worldwide, but the size of the data from each city differs widely
e.g. there are 36,500 businesses in Las Vegas, but only 530 in Toronto
To build a recommendation system, we first must clean the data and establish a clear goal for recommendations
Filtering and selecting the dataset¶
There are many types of businesses categories in the dataset. These categories are included as tags in the data and businesses can have multiple tags.
# Number of business in total
business_df['business_id'].count()
Business Category¶
To get an idea of the types of busineesses included in the dataset, we can look at the "Categories" tag in the Businesses table.
categories, num_categories, top_categories = common_categories(business_df)
print("There are {} unique business categories in the dataset".format(num_categories))
print("The top categories by count are")
print('\n'.join('\t{}:{}'.format(*k) for i,k in enumerate(top_categories)))
Location¶
Next, we explore the data to select the best city with which to work. Because many cities are actually larger metropolitan areas that include several cities, we divide the data by state and look at the counts by state. We would like choose a location that has the most businesses, and restaurants in particular, but also has the most reviews for those businesses (restaurants).
# Business counts
business_location_counts, top_restaurant_counts = data_location(business_df, business_df)
print("Number of all business and restaurant by state")
print('\n'.join('\t{}:{}'.format(*k) for i,k in enumerate(top_restaurant_counts[:12])))
# Reviews counts
review_location_counts, top_restaurant_review_counts = data_location(review_df, business_df)
print("Number of reviews for all business and restaurant by state")
print('\n'.join('\t{}:{}'.format(*k) for i,k in enumerate(top_restaurant_review_counts[:12])))
# Check-in counts
checkin_location_counts, top_restaurant_checkin_counts = data_location(checkin_df, business_df)
print("Number of check-ins for all business and restaurant by state")
print('\n'.join('\t{}:{}'.format(*k) for i,k in enumerate(top_restaurant_checkin_counts[:12])))
# Tip counts
tips_location_counts, top_restaurant_tips_counts = data_location(tip_df, business_df)
print("Number of tips for all business and restaurant by state")
print('\n'.join('\t{}:{}'.format(*k) for i,k in enumerate(top_restaurant_tips_counts[:12])))
Time¶
To train and evaluate the recommender system, the dateset must be split by time. The first time period is used to train the recommender system and the later time period is used to evaluate it. To find the appropriate train-test split, the number of reviews over time is analyzed
plot_reviews_over_time(counts, cummulative_counts, bin_edges, cutoff)

Utility Matrix¶
Constructing the utility matrix¶
if $r_{ij}$ is the rating user $i$ gave item $j$,
$$ R_{ij} = \left\{ \begin{array}{ll} r_{ij} & \text{if user $i$ reviewed item $j$} \\ 0 & \mathrm{otherwise} \\ \end{array} \right. $$Users don't rate many restaurants¶
# plot review counts per user
plot_review_counts(M)

The utility matrix is sparse¶
# plot utility matrix
plot_sparse_matrix(M)

Test set¶
Evaluating the recommendation system will be done by comparing predicted star rating for users with reviews before and after the training/testing cut-off.
Users with rating only after the cut-off is disregarded, and not included in the utility matrix, since training on "future" data is not realistic in a "real-world" setting.
The utility matrix is constructed with the test indices masked off and the users with ratings after the cut-off removed
Methods: Content-Based vs Collaborative Filtering Recommendation¶
Content-Based¶
In content-based recommendation systems, profiles are created for items and for users.
Creating good profiles relies on designing (or learning) good features
Predictions are based on similarities between items or similarities between users
Collaborative Filtering¶
Instead of constructing item and user profiles, users are represented by their corresponding row in the utility matrix and items by their corresponding column.
Matrix factorization based predictions¶
User's rating of items are not random. They are goverened by ... something. We don't really know. Ratings could depend on many factors relating users, items, and external factors.
We assume there are some (latent) factors that can be regarded as responsible for how users review restaurants. Without explicitly constructing these factors, we can construct matrices to represent them.
The utility matrix $R$ can be factorized in the following way
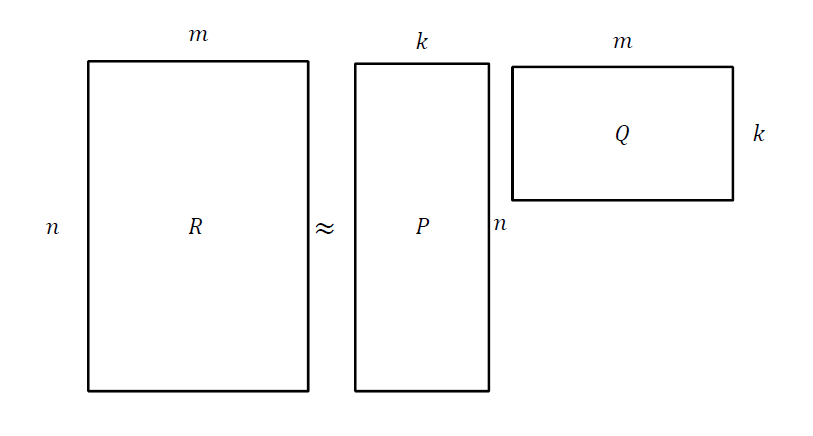
$n$: number of users
$m$: number of items (businesses)
$k$: number of factors we allow for deciding ratings
The goal is to factor the utility matrix to reduce the error
i.e find $P$ and $Q$ so that the error is minimized
Root mean square error
$ R \approx PQ$
prediction for user $i$ on item $j$: $S_{ij} = (PQ)_{ij}$
$$ RMSE = \sqrt{\frac{1}{n} \sum_{i,j}\left|(s_{i,j} - r_{i,j})^2\right|} $$Instead of explicitly performing the $PQ$ multiplication, we can compute $S_{ij} = P_{i,:}Q_{:,j}$ only for non-zero values in the utility matrix
Finding optimal $P$ and $Q$¶
Linear regression and least squares¶
In linear regression, we had a data matrix $\mathbf{X}$ and a target $\mathbf{y}$ and we wanted to find a coefficient vector $\mathbf{w}$ so that
$$ \mathbf{y} = \mathbf{X}\mathbf{w} + \lambda \mathbf{w}^T\mathbf{w} $$
To find $\mathbf{w}$ that minimized the MSE $\left(MSE = \frac{1}{N} \displaystyle\sum_{n=1}^N (\mathbf{w}^T\mathbf{x}_n - y_n)^2 + \lambda\|\mathbf{w}\|_2^2 \right)$ there is a closed-formed solution:
$$ \mathbf{w} = \left(\mathbf{X}^T\mathbf{X} + \lambda\mathbf{I} \right)^{-1}\mathbf{X}^Ty $$Multivariable linear regression and least squares¶
If instead of predicting a single target value, we want to predict a vector for each instance $\mathbf{x}_i$, we need to find a matrix of coefficients

and the closed-form solution is $$ \mathbf{W} = \left(\mathbf{X}^T\mathbf{X} + \lambda\mathbf{I} \right)^{-1}\mathbf{X}^T\mathbf{Y} $$
The multivariable regression problem $$\mathbf{Y}=\mathbf{X}\mathbf{W} + \lambda \|\mathbf{W}\|^2$$ looks very similar to the matrix factorization problem $$ \mathbf{R} = \mathbf{P}\mathbf{Q} + \lambda\left(\|\mathbf{P}\|^2 + \|\mathbf{Q}\|^2\right) $$
except in MF,
$$ {}$$
Therefore the objective is non-convex
and the problem is NP-hard
Alternating least squares¶
Using alternating least squares, we can fix one matrix, solve for the other, then use those values to fix the second matrix and solve for the first. We continue to alternate between solving both until the matrices converge
Repeat:
- Fix $\mathbf{Q}$. Solve for $\mathbf{P}$
- $\mathbf{P} =\left(\mathbf{Q}\mathbf{Q}^T + \lambda\mathbf{I}\right)^{-1}\mathbf{Q}\mathbf{R}$
- Fix $\mathbf{P}$. Solve for $\mathbf{Q}$
- $\mathbf{Q} =\left(\mathbf{P}\mathbf{P}^T + \lambda\mathbf{I}\right)^{-1}\mathbf{P}\mathbf{R}^T$
Now, in each step the problem is just a multivariable linear regression where the feature matrix is $\mathbf{Q}$ (or $\mathbf{P}$) and the coefficient matrix is $\mathbf{P}$ (or $\mathbf{Q}$)
Note about regularization¶
modify the objective value to use weighted-$\lambda$-regularization1 $$ \mathbf{R} = \mathbf{P}\mathbf{Q} + \lambda\left(\mathbf{n}_u \|\mathbf{P}\|^2 + \mathbf{n}_b\|\mathbf{Q}\|^2\right) $$
to include $n_u$, the number of businesses each user reviewed, and $n_b$, the number of users that reviewed each business
Repeat:
- Fix $\mathbf{Q}$. Solve for $\mathbf{P}$
- $\mathbf{P} =\left(\mathbf{Q}\mathbf{Q}^T + \mathbf{n}_u\lambda\mathbf{I}\right)^{-1}\mathbf{Q}\mathbf{R}$
- Fix $\mathbf{P}$. Solve for $\mathbf{Q}$
- $\mathbf{Q} =\left(\mathbf{P}\mathbf{P}^T + \mathbf{n}_b\lambda\mathbf{I}\right)^{-1}\mathbf{P}\mathbf{R}^T$
[1] Zhou, Y. et al., 2008. Large-scale parallel collaborative filtering for the netflix prize. In Lecture Notes in Computer Science (including subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). pp. 337-348.
Results¶
for lmbda, k in param_pairs:
if (lmbda,k)not in results.keys() or results[(lmbda,k)]['P'] is None:
print('lambda {}, k {}'. format(lmbda,k))
P, Q, train_errors, validation_errors, test_errors = alsq(
R, M, k, lmbda, max_iters, train_indxs, validation_indxs, test_indxs)
results[(lmbda, k)] = {'train': train_errors,
'validate': validation_errors,
'test': test_errors,
'P': P,
'Q': Q}
plot_results_reg(results,lmbdas,ks)

Evaluate¶
# Baseline
R = scipy.sparse.csc_matrix(R,dtype=np.uint32) #fix sum overflow!!!
count_nnz = R.getnnz(0)
sums = np.array(R.sum(0)).flatten()
means = np.zeros(len(count_nnz))
for i,c in enumerate(count_nnz):
if c != 0:
means[i] = sums[i]/c
overall_mean = np.mean(means[means!=0])
means[means==0]=overall_mean
avg_errors = []
for i,j in test_indxs:
actual = M[i,j]
avg = means[j]
if avg==0:
avg = overall_mean
avgerr = rmse_pred(actual, avg)
avg_errors += [avgerr]
# Average Baseline error
bl_err = np.mean(avg_errors)
print('Average Baseline MSE: {:.4f}'.format(bl_err))
plt.figure()
plt.hist(avg_errors)
plt.xlabel('MSE')
plt.title('MSE for test set')

#Calculate MSE for each parameter pair
MF_errors = {(l,k):[] for l,k in results.keys()}
MFVal_errors = {(l,k):[] for l,k in results.keys()}
#Matrix Factorization
for l,k in param_pairs:
if results[(l,k)]['P'] is not None:
P = results[(l,k)]['P']
Q = results[(l,k)]['Q']
for i,j in validation_indxs:
actual = M[i,j]
MF = predict(P,Q,i,j)
MFerr = rmse_pred(actual, MF)
if len(MFerr)>0:
MFVal_errors[l,k] += [MFerr[0]]
for i,j in test_indxs:
actual = M[i,j]
MF = predict(P,Q,i,j)
MFerr = rmse_pred(actual, MF)
if len(MFerr)>0:
MF_errors[l,k] += [MFerr[0]]
valerr = np.sqrt(np.sum(MFVal_errors[l,k])/len(MFVal_errors[l,k]))
testerr = np.sqrt(np.sum(MF_errors[l,k])/len(MF_errors[l,k]))
print('lambda = {}, k = {} \t| val error {:.4f} \t| test error {:.4f}'.format(l,k,valerr, testerr))
#effect of lambda
fig = plt.figure()
for k in ks:
errs = [np.sqrt(np.sum(MFVal_errors[l,k])/len(MFVal_errors[l,k])) for l in lmbdas]
plt.plot(lmbdas,errs,label='k={}'.format(k))
plt.legend(loc=4)
plt.title('Validataion MSE')
plt.xlabel('$\lambda$')

#effect of k
fig = plt.figure()
for l in lmbdas:
errs = [np.sqrt(np.sum(MFVal_errors[l,k])/len(MFVal_errors[l,k])) for k in ks]
plt.plot(ks,errs,label='$\lambda$={}'.format(l))
plt.legend(loc=4)
plt.title('Validataion MSE')
plt.xlabel('$k$')
